
12 Lighting for Small Spaces to Make Them Feel Larger - light small
Different mechanical mounting systems are used to connect a lens to a camera, ensuring both good focus and image stability. The mount is defined by the mechanical depth of the mechanics (flange focal distance), along with its diameter and thread pitch (if present). It’s important that the lens flange focal distance and the camera mount flange distance are exactly the same, or focusing issues may arise. The presence of a threaded mechanism allows some adjustment to the back focal distance if needed. For example, in the Opto Engineering® PCHI series lenses, the back focal adjustment is needed to adjust the focus for a different field of view.
The F-number affects the optics depth of field (DoF), that is the range between the nearest and farthest location where an object is acceptably in focus. Depth of field is quite a misleading concept because physically there is one and only one plane in object space that is conjugate to the sensor plane. However, being mindful of diffraction, aberration and pixel size, we can define an “acceptable focusing distance” from the image conjugate plane, based on subjective criteria. For example, for a given lens, the acceptable focusing distance for a precision gauging application requiring a very sharp image is smaller than for a coarse visual inspection application.
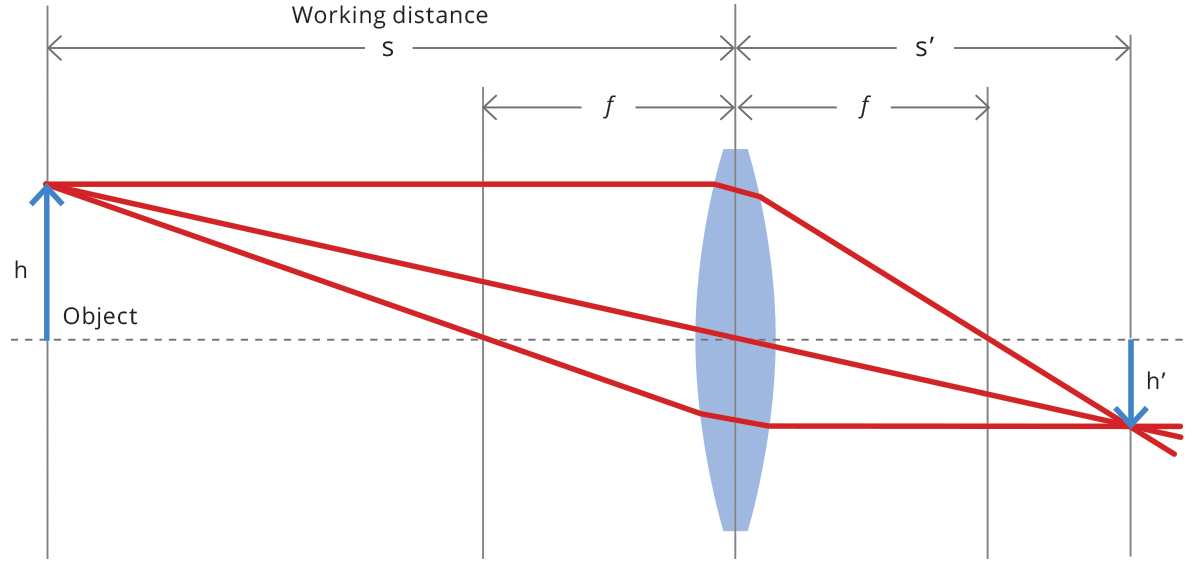
The focal length and the focus plane coincide only when the object is placed at an infinite distance, indeed beams from a point on the object can be considered as parallel. When instead the distance from the object is ‘short’ (rule of thumb: <10x Focal length), we are in macro mode and the focus plane is placed further away from the optical system compared to the focal length.
A certain number of parameters must be considered when choosing optics, depending on the area that must be imaged (field of view), the thickness of the object or features of interest (depth of field), the lens to object distance (working distance), the intensity of light, the optics type (telecentric/entocentric/pericentric), etc.
The main features of most optical systems can be calculated with a few parameters, provided that some approximation is accepted. The paraxial approximation requires that only rays entering the optical system at small angles with respect to the optical axis are taken into account. The thin lens approximation requires the lens thickness to be considerably smaller than the radii of curvature of the lens surfaces: it is thus possible to ignore optical effects due to the real thickness of the lenses and to simplify ray-tracing calculations. Furthermore, assuming that both object and image space are in the same medium (e.g. air), we get the following fundamental equation:
AI-based computer vision based on deep learning is trained on volumes of data. It is not uncommon to see hundreds of thousands and millions of digital images used to train and develop deep neural network models. For more information, see What’s the difference Between Artificial Intelligence, Machine Learning, and Deep Learning?.
This post was written to enable the beginner developer community, especially those new to computer vision and computer science. NVIDIA recognizes that solving and benefiting the world’s visual computing challenges through computer vision and artificial intelligence requires all of us. NVIDIA is excited to partner and dedicate this post to the Black Women in Artificial Intelligence.
For optical systems used in machine vision, in which rays reflected from a faraway object are focused onto the sensor plane, the focal length can be also seen as a measure of how much area is imaged on the sensor (Field of View): the longer the focal length, the smaller the FoV and vice versa (this is not completely true for some particular optical systems, e.g. in astronomy and microscopy).
Multimodal conversational AI combines the capabilities of conversational AI with computer vision in multimedia conferencing applications, such as NVIDIA Maxine.
Optical camerameaning
Segmentation tasks classify pixels belonging to a certain category, either individually by pixel (semantic image segmentation) or by assigning multiple object types of the same class as individual instances (instance image segmentation). For example, a self-driving car segments parts of a road scene as drivable and non-drivable space.
Since fixed focal length lenses also follow the previous equation, it is possible to calculate the required focal length given the magnification and working distance, or the required working distance given the sensor size, field of view and focal length, etc. (some examples are given at the end of this section). For macro and telecentric lenses instead, the working distance and magnification are typically fixed.
cameralens是什么
Computer vision is helping to teach and master seeing, just like conversational AI is helping teach and master the sense of sound through speech, in applications of recognizing, translating, and verbalizing text: the words we use to define and describe the physical world around us.
Computer vision’s real world use and reach is growing and its applications in turn are challenging and changing its meaning. Computer vision, which has been in some form of its present existence for decades, is becoming an increasingly common phrase littered in conversation, across the world and across industries: computer vision systems, computer vision software, computer vision hardware, computer vision development, computer vision pipelines, computer vision technology.

The detection, classification, segmentation, and synthesis tasks mentioned earlier typically are AI-based computer vision algorithms because of the accuracy and robustness that can be achieved. In many instances, AI-based computer vision algorithms can outperform traditional algorithms in terms of these two performance metrics.
Primelens
In traditional computer vision, a specific set of instructions perform a specific task, like detecting corners or edges in an image to identify windows in an image of a building.
In other words, computer vision fundamentally intakes image data or image datasets as inputs, including both still images and moving frames of a video, either recorded or from a live camera feed. Computer vision enables devices to have and use human-like vision capabilities just like our human vision system. In human vision, your eyes perceive the physical world around you as different reflections of light in real-time.
To see how NVIDIA enables the end-to-end computer vision workflow, see the Computer Vision Solutions page. NVIDIA provides models plus computer vision and image-processing tools. We also provide AI-based software application frameworks for training visual data, testing and evaluation of image datasets, deployment and execution, and scaling.
Telephotolens
Computer vision can also be used broadly to describe how other types of sensors like light detection and ranging (LiDAR) and radio detection and ranging (RADAR) perceive the physical world. In self-driving cars, computer vision is used to describe how LiDAR and RADAR sensors work, often together and in-tandem with cameras to recognize and classify people, objects, and debris.
Image synthesis techniques create synthetic data by morphing existing digital images to contain desired content. Generative adversarial networks (GANs), such as EditGAN, enable generating synthetic visual information from text descriptions and existing images of landscapes and people. Using synthetic data to compliment and simulate real data is an emerging computer vision use case in logistics using vision AI for applications like smart inventory control.
AI-based computer vision or vision AI relies on algorithms that have been trained on visual data to accomplish a specific task, as opposed to programmed, hard-coded instructions like that of image processing.
AI-based neural networks teach themselves, depending on the data the algorithm was trained on. AI-based computer vision is like learning from experience and making predictions based on context apart from explicit direction. The learning process is akin to when your eye sees an unfamiliar object and the brain tries to learn what it is and stores it for future predictions.
There is more to the term and field of computer vision than meets the eye, both literally and figuratively. Computer vision is also referred to as vision AI and traditional image processing in specific non-AI instances, and machine vision in manufacturing and industrial use cases.
Camera lens
Similarly, computer vision helps teach and master the sense of sight through digital image and video. More broadly, the term computer vision can also be used to describe how device sensors, typically cameras, perceive and work as vision systems in applications of detecting, tracking and recognizing objects or patterns in images.
To understand the different domains within computer vision, it is important to understand the techniques on which computer vision tasks are based. Most computer vision techniques begin with a model, or mathematical algorithm, that performs a specific elementary operation, task, or combination. While we classify traditional image processing and AI-based computer vision algorithms separately, most computer vision systems rely on a combination depending on the use case, complexity, and performance required.
Now that we have covered the fundamentals of computer vision, we encourage you to get started developing computer vision. We recommend that beginners get started with the Vision Programming Interface (VPI) Computer Vision and Image Processing Library for non-AI algorithms or one of the TAO Toolkit fully-operational, ready-to-use, pretrained AI models.
C-mount is the most common optics mount in the industrial market. It is defined by a flange focal distance of 17.526 mm, a diameter of 1” (25.4 mm) with 32 threads per inch.
CS-mount is a less popular and 5 mm shorter version of the C-mount, with a flange focal distance of 12.526 mm. A CS-mount camera presents various issues when used together with C-mount optics, especially if the latter is designed to work at a precise back focal distance.
Pinholecamera
Deep learning-based computer vision models are a subset of machine learning-based computer vision. The “deep” in deep learning derives its name from the depth or number of the layers in the neural network. Typically, a neural network with three or more layers is considered deep.
F-mount is a bayonet-style mount originally developed by Nikon for its 35 mm format cameras and is still found in most of its digital SLR cameras. It is commonly used with bigger sensors, e.g. full-frame or line-scan cameras. Lenses can be easily swapped out thanks to the bayonet mount, but no back focal adjustment is possible.
where p is the sensor pixel size (in microns), M is the lens magnification and k is a dimensionless parameter that depends on the application (reasonable values are 0.008 for measurement applications and 0.015 for defect inspection). For example, taking p = 5.5 µm and k = 0.015, a lens with 0.25X mag and WF/# = 8 has an approximate DoF = 10.5 mm.
Machine learning computer vision is a type of AI-based computer vision. AI-based computer vision based on machine learning has artificial neural networks or layers, similar to that seen in the human brain, to connect and transmit signals about the visual data ingested. In machine learning, computer vision neural networks have separate and distinct layers, explicitly-defined connections between the layers, and predefined directions for visual data transmission.
Macro and telecentric lenses are designed to work at a distance comparable to their focal length (finite conjugates), while fixed focal length lenses are designed to image objects located at a much greater distance than their focal length (infinite conjugates). It is thus convenient to classify the first group by their magnification, which makes it easier to choose the proper lens given the sensor and object size, and the latter by their focal length.
where s (s’ ) is the object (image) position with respect to the lens, customarily designated by a negative (positive) value, and f is the focal length of the optical system (cf. Fig. 1). The distance from the object to the front lens is called working distance, while the distance from the rear lens to the sensor is called back focal distance. Henceforth, we will be presenting some useful concepts and formulas based on this simplified model, unless otherwise stated.
VAT IT02011230204 Fiscal code and registration number at Mantova Business Register 02011230204 Nr. REA: MN-216669 - Share Capital: 205.258,00 € 沪ICP备12040578号-2
This is why a spacer kit is supplied with Opto Engineering® telecentric lenses including instructions on how to tune the back focal length at the optimal value.
The basic purpose of a lens of any kind is to collect the light scattered by an object and recreate an image of the object on a light-sensitive ‘sensor’ (usually CCD or CMOS based).
Typical F-numbers are F/1.0, F/1.4, F/2, F/2.8, F/4, F/5.6, F/8, F/11, F/16, F/22, etc. Every increment in the F-number (smaller aperture) reduces incoming light by a factor of 2. The given definition of F-number applies to fixed focal length lenses where the object is located ‘at infinity’ (i.e. a distance much greater than its focal length). For macro and telecentric lenses where objects are at a closer distance, instead, the working F/# (wF/#)is used. This is defined as:
While computer vision tasks cover a wide breadth of perception capabilities and the list continues to grow, the latest techniques support and help solve use cases involving detection, classification, segmentation, and image synthesis.
Mxx-mounts are different types of camera mounts defined by their diameter (e.g. M72, M42), thread pitch (e.g. 1 mm, 0.75 mm) and flange focal distance. They are a common alternative to the F-mount for larger sensors.
Classification techniques determine what object exists within the visual data. For example, in manufacturing, an object recognition system classifies different types of bottles to package. In agriculture, farmers are using classification to identify weeds among their crops.
To help enable emerging computer vision developers everywhere, NVIDIA is curating a series of paths to mastery to chart and nurture next-generation leaders. Stay tuned for the upcoming release of the computer vision path to mastery to self-pace your learning journey and showcase your #NVCV progress on social media.
Simply put, computer vision enables devices, including laptops, smartphones, self-driving cars, robots, drones, satellites, and x-ray machines to perceive, process, analyze, and interpret data in digital images and video.
Widelens
Every optical system is characterized by an aperture stop, that determines the amount of light that passes through it. For a given aperture diameter d and focal length f we can calculate the optics F-number:
For common optical systems, in thin lens approximation, the focal length is the distance over which collimated rays coming from infinity converge to a point on the optical axis.
Similarly, computer vision devices perceive pixels of images and videos, detecting patterns and interpreting image inputs that can be used for further analysis or decision making. In this sense, computer vision “sees” just like human vision and uses intelligence and compute power to process input visual data to output meaningful insights, like a robot detecting and avoiding an obstacle in its path.
Detection tasks locate, and sometimes track, where an object exists in an image. For example, in healthcare for digital pathology, detection could involve identifying cancer cells through medical imaging. In robotics, software developers are using object detection to avoid obstacles on the factory floor.
Optical lens
Each camera mount is more commonly used with certain camera sensor formats. The most typical sensor formats are listed below. It is important to remember that these are not absolute values – i.e. two cameras listed with the same sensor format may differ substantially from one another in terms of aspect ratio (even if they have the same sensor diagonal). For example, the Sony Pregius IMX250 sensor is listed as 2/3” and has an active area of 8.45 mm x 7.07 mm. The CMOSIS CMV2000 sensor is also listed as 2/3” format but has an active area of 11.26 mm x 5.98 mm.
AI-based computer vision algorithms mimic the human vision system more closely by learning from and adapting to visual data inputs, making them the computer vision models of choice in most cases. That being said, AI-based computer vision algorithms require large amounts of data and the quality of that data directly drives the quality of the model’s output. But, the performance outweighs the cost.
On the other hand, image processing performs a specific manipulation of an image that can be then used for further processing with a vision algorithm. For instance, you may want to smooth or compress an image’s pixels for display or reduce its overall size. This can be likened to bending the light that enters the eye to adjust focus or viewing field. Other examples of image processing include adjusting, converting, rescaling, and warping an input image.
Different computer vision tasks mimic the human vision system, performing, automating, and enhancing functions similar to the human vision system.
A common F-number value is F/8 since smaller apertures could give rise to diffraction limitations, while lenses with larger apertures are more affected by optical aberrations and distortion. A rough estimate of the field depth of telecentric and macro lenses (or fixed focal length lenses used in macro configuration) is given by the following formula:
The focal length is a typical characteristic of an optical system. It is a measure of how strongly the system converges or diverges rays of light. If collimated rays converge to a physical point, the lens is said to be positive (convex), whereas if rays diverge the focus point is virtual and the lens is said to be negative (concave). All optics used in machine vision applications are overall positive, i.e. they focus incoming light onto the sensor plane. CCTV lenses are commonly identified by their focal length, expressed in millimeters (12mm, 25mm, 35mm, etc.).
Many cameras are found not to respect the industrial standard for C-mount (17.52 mm), which defines the flange-to-detector distance (flange focal length). Besides all the issues involved with mechanical inaccuracy, many manufacturers don’t take into the due account the thickness of the detector’s protection glass which, no matter how thin, is still part of the actual flange to detector distance.



 Ms.Cecilia
Ms.Cecilia 
 Ms.Cecilia
Ms.Cecilia